Automated test code for web applications brings advantages but also novel issues, above all the test code fragility problem. Indeed, during the evolution of the web application under test, existing test code may easily break and testers have to correct it. One of the major cost factors is the manual effort necessary to repair broken web element locators - lines of source code identifying the web elements (e.g. form fields and buttons) to interact with.
Existing tools create simple and brittle locators, and even minor modifications of the DOM structure cause their failure, thus are inadequate to be used for regression testing.
Our robust locator creation algorithms, instead, are capable of automatically generating robust XPath-based locators that are likely to work also when new releases of the web application are created.
Algorithms
ROBULA (ISSREW 2014) is the first implementation of our algorithm. Basically, ROBULA starts with a generic XPath locator that returns all nodes ("//*"). It then iteratively refines the locator until only the element of interest is selected. In such iterative refinement, the algorithm applies four refinement transformations (see the ISSREW paper), according to a set of heuristic XPath specialisation steps. ROBULA has been developed in order to create very short and simple XPath expressions, with the goal to increase their resilience to changes. The results from a preliminar empirical evaluation show that XPath locators produced by ROBULA are substantially more robust than absolute and relative locators, generated by state of the practice tools such as FirePath.
ROBULA+ (JSEP 2016) enhances our previous algorithm with several improvements: (i) the adoption of a prioritisation strategy, to rank candidate XPath expressions by heuristically estimated attribute robustness, useful when multiple attributes are available in a DOM element; (ii) the adoption of a blacklisting technique, to exclude attributes that are recognized to be intrinsically fragile; (iii) the usage of textual information for building the predicates composing the XPath locators; text can represent a potentially reliable anchor when the web application evolves; (iv) the usage of multiple attributes for the same node in the XPath locators; (v) the ability of creating locators independent from the specific DOM element type (i.e., "*" specialization). From our empirical experimentations emerges that the locators produced by ROBULA+ are by far more robust than the ROBULA ones and that they are significantly better in terms of robustness than all the other kinds of locators considered in the study.
Main publication
-
Maurizio Leotta, Andrea Stocco, Filippo Ricca, Paolo Tonella.
ROBULA+: An Algorithm for Generating Robust XPath Locators for Web Testing.
Journal of Software: Evolution and Process, Volume 28, Issue 3, pp.177-204, Editors: Gerardo Canfora, Darren Dalcher, David Raffo. John Wiley & Sons, 2016.
DOI: 10.1002/smr.1771, ISSN: 2047-7481.
Previous publication
-
Maurizio Leotta, Andrea Stocco, Filippo Ricca, Paolo Tonella.
Reducing Web Test Cases Aging by means of Robust XPath Locators.
In: Proceedings of 25th IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW 2014), 3-6 November 2014, Napoli, Italy, pp.449-454, IEEE, 2014.
DOI: 10.1109/ISSREW.2014.17, ISBN: 978-1-4799-7377-4.
Algorithm's Implementations
Firefox Add-On
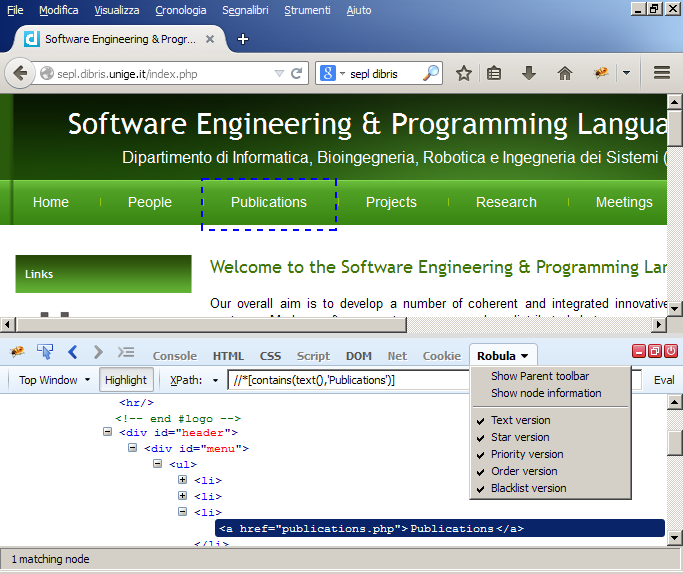
This implementation allows to create ROBULA/ROBULA+ locators by simply clicking on the web page elements. It has been created by modifying the existing add-on FirePath (release 0.9.7). It requires Firefox (tested with the release 31) and the add-on FireBug (tested with the release 2.0.7). Note that, from Firefox 34 the add-on no longer works properly (we are working to fix the problem). Download ROBULA Firefox Add-on (61 kB).
Setting the add-on for ROBULA:
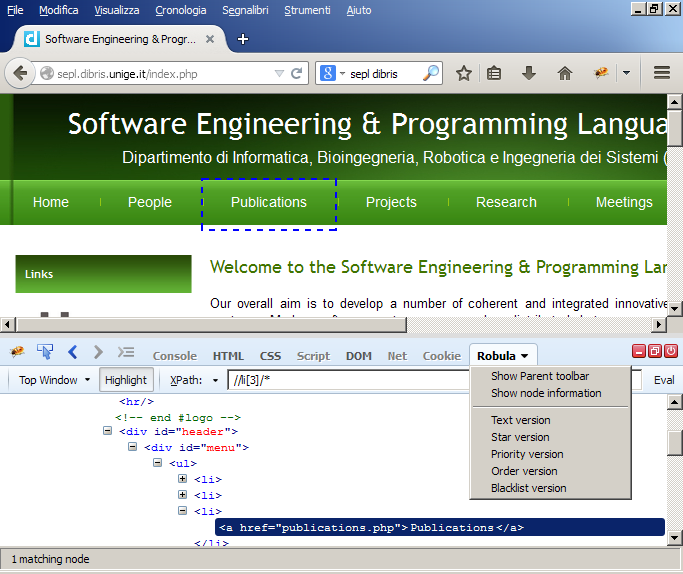
Setting the add-on for ROBULA+ (recommended):